
Project Description
The task in this project is to predict the user's rating for a given item_id and the user's features.
Using this model, we recommend to each customer a set of items by ranking the predicted ratings.
In the dataset, there are several interesting features, such as age, body size, bust size, height, and review text that is worth discovering in the model training process.
However, some features are not easy to obtain before the user posts the rating.
In our project, we want to recommend to every customer accurate items set even though some are first-time customers.
Therefore, a more reasonable way for building our predictive model is to discard those features such as review text and review summary that are not easily observed
in the first place. Nevertheless, the way that we don’t use text data doesn’t mean the text data is useless.
Text mining is still a worth discovering method since it provides valuable information for each item in the training set.
Code for this project can be found in my GitHub Repository
Model Design
Latent Factor is the main method we are using in this project and we implemented 3 different models including one baseline model. The training and validation sets are split in a 7:3 ratio. The training data contains 150K observations and the validation data contains 45K observations.
Baseline Model
In our baseline model, we first implemented the latent factor model and assigned a
unique beta for each user_id and item_id that appear in the training set. We also apply
a regularizer containing two lambdas.
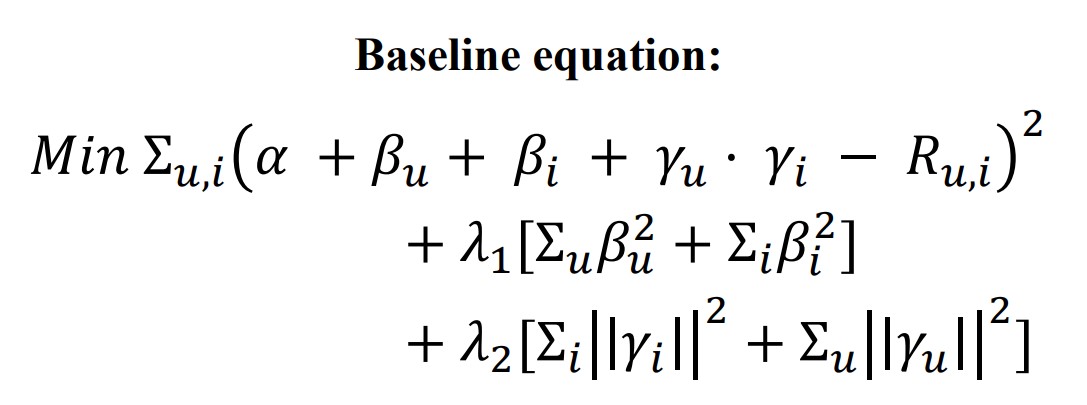
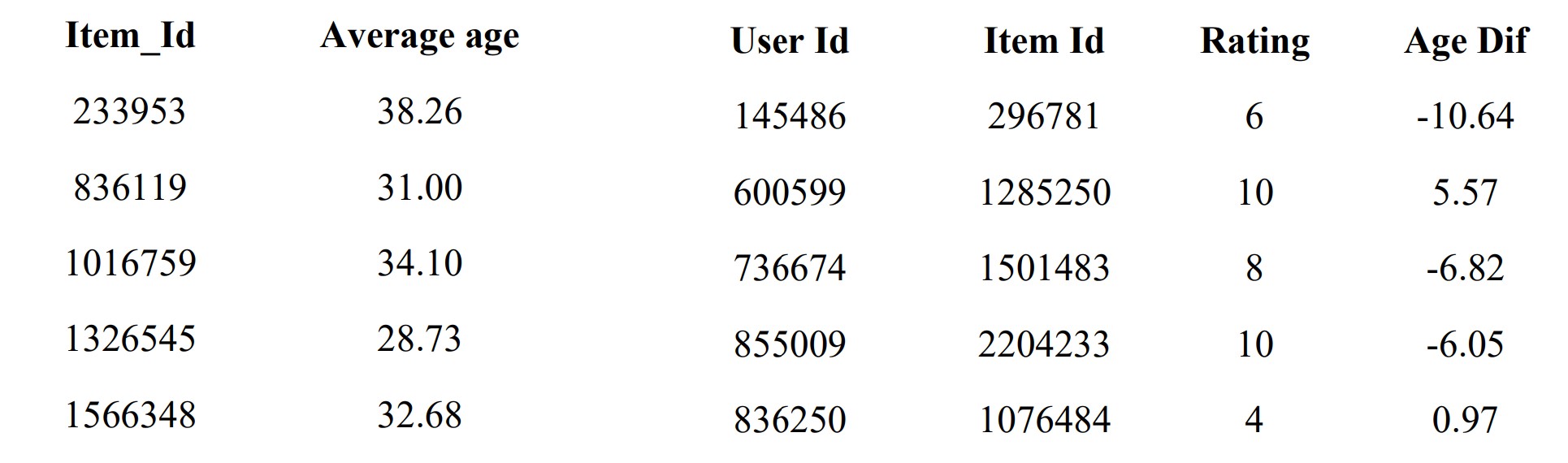
To get more information on the user and item interaction, we believe that the difference between a particular user's age and the item's average might be a strong factor that affects the user's preference and therefore the rating. We first calculate the average buying age for each item and the difference in age for each observation. In this dataset, some users did not provide their ages in their reviews. To solve this problem, the global average age in training data was used to replace those missing age values.
Select/Design Models
To optimize the baseline model, we first apply Adam as the model optimizer and set the learning rate at 0.05. In the training step,
we implement the batch-based model and then run 300 iterations of gradient descent to fit our model. After several experiments,
we found that setting too many iterations might cause the model to overfit. For the regularizer, we utilize two lambdas.
We also try the heuristic mentioned previously to invent two models. In the following models, we mainly focus on using
the age_diff feature that we just created to refine our baseline models. In the first model, we implement a regression model after we calculated the
prediction results using the baseline model. The main reason for using a regression model on the age_dif feature is because it’s easy to investigate the influence of age_dif using a basic statistical model. After running a regression model in the training set, we got a theta and a coefficient of the feature, and then further apply the theta and coefficient for the validation set.
Model B
The training MSE before applying the regression method is 1.65. Compared with the MSE in the baseline, the model in the training set improved by 4%. However, when we calculate the MSE on validation data, the MSE increases to 2.06. This model performs extremely badly on the validation set might be because the age_diff feature is not as significant as we thought previously. The other reason might be the fact that the regression model is prone to overfitting the model. The method in which we implement the regression afterward might also be problematic. However, by implementing this model, we know that the age_diff is influencing the expected rating negatively. This finding indicates that users are more likely to buy items that have a similar average age to their ages.
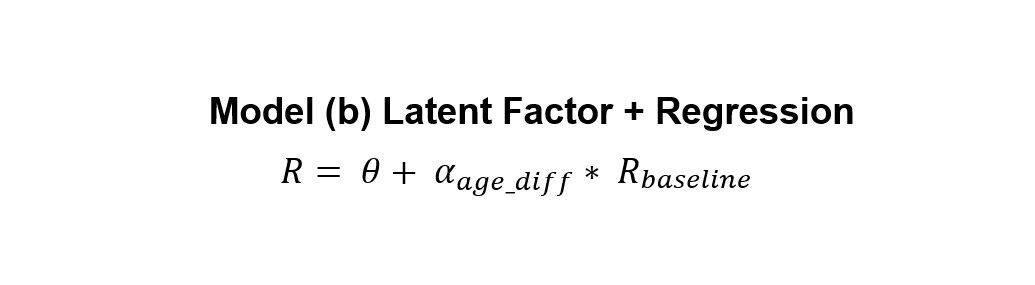
### Model C We create our second model by refining model (c). To solve the problem of training coefficient after we finished the latent factor model. We add one trainable variable δi inthe baseline model. The δi is the coefficient of age_dif for each item and we train the δi with the variables in the baseline model altogether. To solve the overfitting problem on δi, we also apply λ3 for the regularizer. In the training process, we try to minimize the following equation:
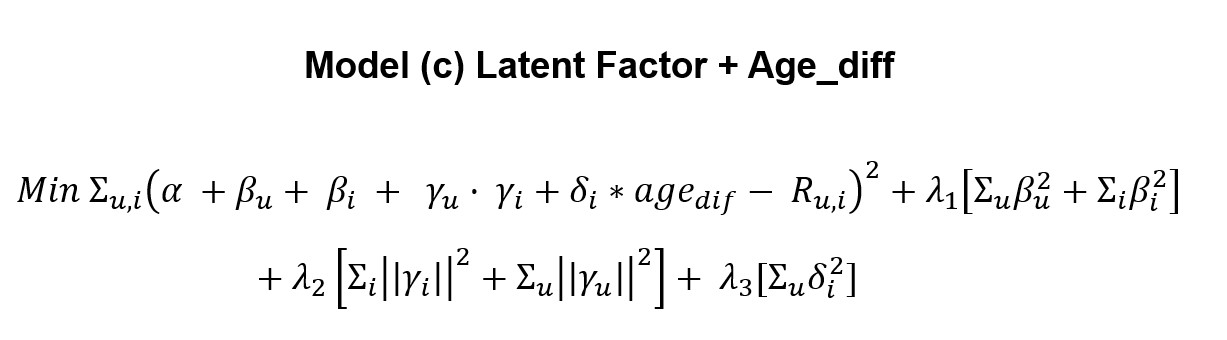

Moreover, the regression model is probably not a suitable model for this kind of prediction because the model is not flexible enough to predict the uncertainty in this kind of dataset. Nevertheless, model (c) still provides useful insight that allows us to observe the influence of features easily. In the future model design, we suggest that more features can be used and combined with our baseline model. Text mining is also a feasible method to discover more information in `user/item` interaction.
Finally, our model can be further improved if we implement an extra validation set or maybe hyperparameter tuning. We do not suggest using too complicated a model since it's easy to cause the model to overfit.
This is a final project of CSE258 Web Mining & Recommender Systems in UCSD.
Project PDF Authors: Yueh-HuanHo, ZhixuanCui, ShiQiu