Project Description#
Kaggle Competition Page
The dataset contains details about restaurants and their reviews. The goal of this kaggle competition is to design data mining models to predict the restaurant type using the observed variables.
This is a challenge designed for Master of Business Analytics students at the Rady School of Management, University of California, San Diego.
This competition is also part of the course requirements for MGTA 415 Analyzing Unstructured Data.
Kaggle Leaderboard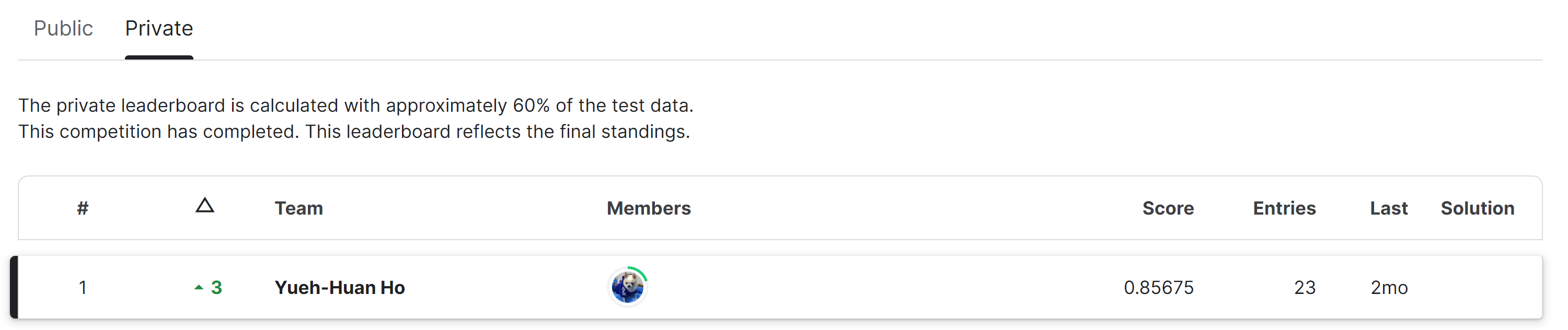
Data Description#
The data is collected from Yelp restaurant reviews.
The dataset contains 60 features in an unstructured way, variables including categrocial, numeric, and text. This project mainly focuses on using customer review to to predict restaurant types.

Feature Engineering#
To transform text data into vector as ML model’s input. I experimented and implemented 2 different methods to vectorize the text data.
- Tf-Idf
- Word embeddings (skip-gram, CBOW)
Preprocess raw text and implement Stopword, Stemming
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
def preprocess_df(df, stemming=False):
# get English stopwords
stop_words = set(stopwords.words('english'))
stop_words.add('would')
stop_words.add('The')
# prepare translation table to translate punctuation to space
translator = str.maketrans(string.punctuation, ' ' * len(string.punctuation))
preprocessed_sentences = []
for i, row in df.iterrows():
sent = row["text"]
sent_nopuncts = sent.translate(translator)
words_list = sent_nopuncts.strip().split()
if stemming == True:
words_list = [ps.stem(word) for word in words_list]
filtered_words = [word for word in words_list if word not in stop_words and len(word) != 1] # also skip space from above translation
preprocessed_sentences.append(" ".join(filtered_words))
df["text"] = preprocessed_sentences
return df
|
Fit TfidfVectorizer
For TfidfVectorizer, the most important parameters is max_df, which has a strong influence on model training.
1
2
3
4
5
6
7
8
9
10
11
12
|
tfidf = TfidfVectorizer(strip_accents=None,
lowercase=True,
preprocessor=None, # applied preprocessor in Data Cleaning
tokenizer=word_tokenize,
use_idf=True,
norm='l2',
smooth_idf=True,
stop_words= 'english',
max_df=0.4,
sublinear_tf=True)
X = tfidf.fit_transform(df_train["text"])
|
Train embedding model
This function provides both skipgram and CBOW for word embedding.
Several hyperparameters such as min_word_count, context were also tested.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
def get_embeddings(inp_data, vocabulary_inv, size_features=100,
mode='skipgram',
min_word_count=2,
context=5):
model_name = "embedding"
model_name = os.path.join(model_name)
num_workers = 15 # Number of threads to run in parallel
downsampling = 1e-3 # Downsample setting for frequent words
print('Training Word2Vec model...')
# use inp_data and vocabulary_inv to reconstruct sentences
sentences = [[vocabulary_inv[w] for w in s] for s in inp_data]
if mode == 'skipgram':
sg = 1
print('Model: skip-gram')
elif mode == 'cbow':
sg = 0
print('Model: CBOW')
embedding_model = word2vec.Word2Vec(sentences, workers=num_workers,
sg=sg,
vector_size=size_features,
min_count=min_word_count,
window=context,
sample=downsampling)
print("Saving Word2Vec model {}".format(model_name))
embedding_weights = np.zeros((len(vocabulary_inv), size_features))
for i in range(len(vocabulary_inv)):
word = vocabulary_inv[i]
if word in embedding_model.wv:
embedding_weights[i] = embedding_model.wv[word]
else:
embedding_weights[i] = np.random.uniform(-0.25, 0.25,
embedding_model.vector_size)
return embedding_weights, embedding_model
|
Preprocess none-text data (numeric, categorical)
This function preprocess non-text data for future model building.
Regex was also used for making variables clean and concise.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
|
def process_attributes(df, test=False):
attribute_list = ['name','stars','review_count','attributes.OutdoorSeating','attributes.BusinessAcceptsCreditCards',\
'attributes.RestaurantsTableService','attributes.RestaurantsReservations','attributes.RestaurantsPriceRange2',\
'attributes.HasTV','attributes.RestaurantsGoodForGroups','attributes.Caters',\
'attributes.RestaurantsTakeOut','attributes.RestaurantsDelivery','attributes.GoodForKids', 'attributes.BikeParking',\
'latitude', 'longitude', 'postal_code', 'is_open', 'text']
if test == False:
attribute_list.append('label')
else:
pass
df = df[attribute_list]
col_names = df.columns
col_name_clean = list(df[attribute_list].columns.str.replace('attributes.', ''))
new_column_names = {column: column.replace('attributes.', '') for column in col_names}
df = df.rename(columns=new_column_names)
d = {'False': 0, 'True': 1}
pattern = r'\b\d+\b(?:\s+\b\d+\b)*\s*'
#clean b'
for col in df:
if col != 'text' and col != 'label' and col != 'name' and col != 'latitude' and col != 'longitude' and col != 'postal_code' and col != 'is_open':
try:
df[col] = df[col].str.extract(r"b'(.*?)'")
df[col] = df[col].map(d)
except:
pass
if col == 'name' or col == 'postal_code':
df[col] = df[col].str.extract(r"b'(.*?)'")
## 0 if Canada postal code 1 if US
if col == 'postal_code':
df[col] = df[col].str.match(pattern)
df = df.fillna(0)
df['text'] = df['name'].astype(str) + ' ' + df['text']
df[['OutdoorSeating','BusinessAcceptsCreditCards','RestaurantsTableService','RestaurantsReservations',\
'RestaurantsPriceRange2','HasTV','RestaurantsGoodForGroups','Caters','RestaurantsTakeOut','RestaurantsDelivery',\
'GoodForKids', 'postal_code', 'is_open', 'BikeParking']] =\
df[['OutdoorSeating','BusinessAcceptsCreditCards','RestaurantsTableService',\
'RestaurantsReservations','RestaurantsPriceRange2','HasTV','RestaurantsGoodForGroups',\
'Caters','RestaurantsTakeOut','RestaurantsDelivery','GoodForKids', 'postal_code', 'is_open', 'BikeParking']].astype('category')
return df
|
Modeling#
In model training, I fitted logistic regression models for both tfidf and word-embedding input. After several hyperparameter tuning, tfidf has better results overall.
Model 1 (text, logit)#
This image shows the final model built for text data. The final model for text data is logistic regression. I also tried RF and boosting tree and the results are not better than logit. Also, consider the sparsity of data and the time for model training, I skipped MLP. As we can see, the result for model 1 is pretty decent and the accuracy scores on testing and validation sets are already over 0.8.
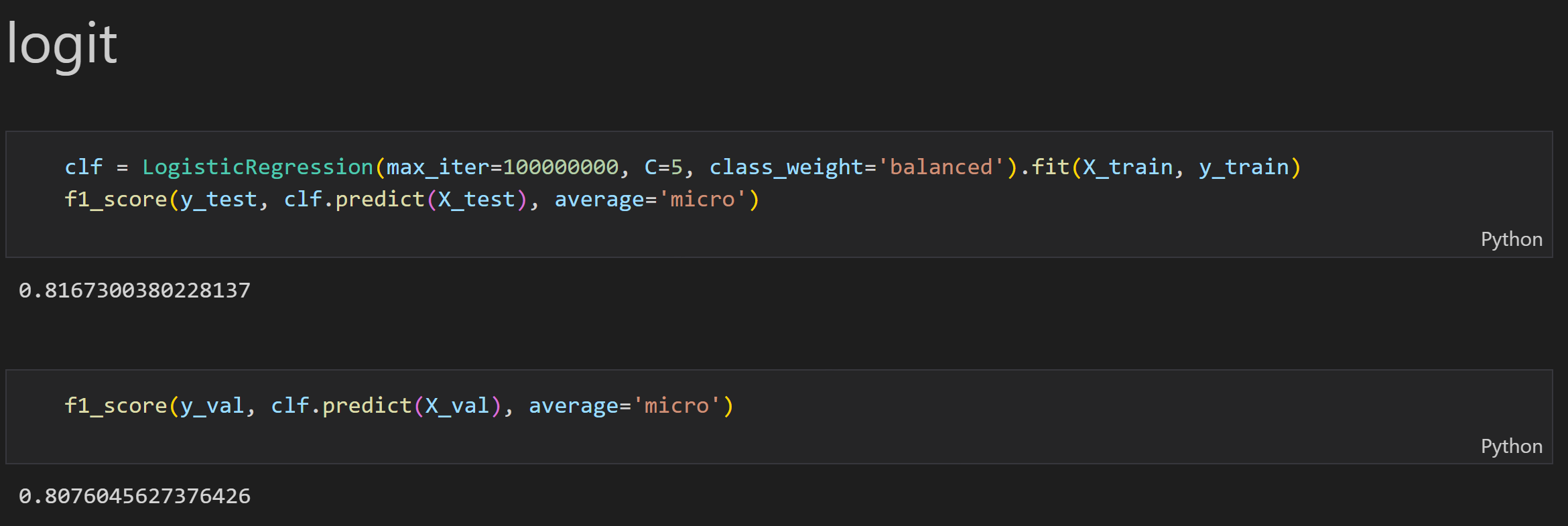
Model 2 (numeric and categorical, RF)#
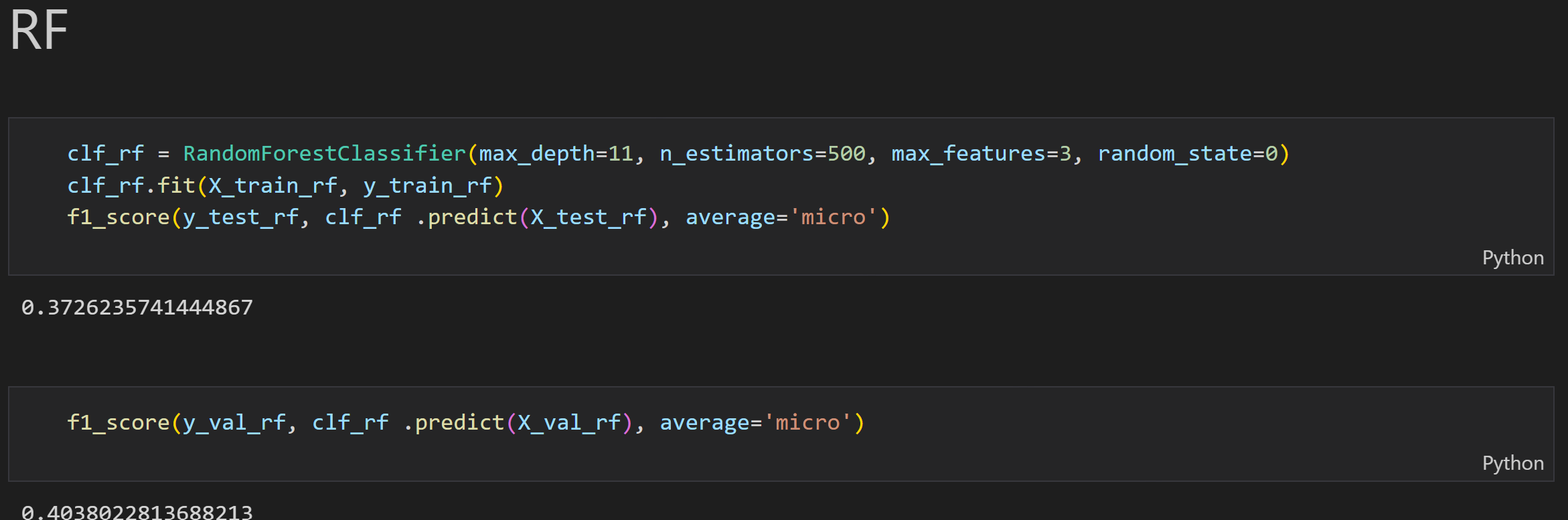
In order to utilize the none-text data, I also trained an RF model to predict the restaurant type. I the next part, I will ensemble Model 1 and Model 2 to create my final model.
As the following image showing, the RF model unsing none-text data doesn’t have decent perfromance. However, this model dose has better performance on certain restaurant types, for example, American resuarant and Canandian restaurant. Considering this finding, I will combine ensemble model 1 with model 2 in the next step.
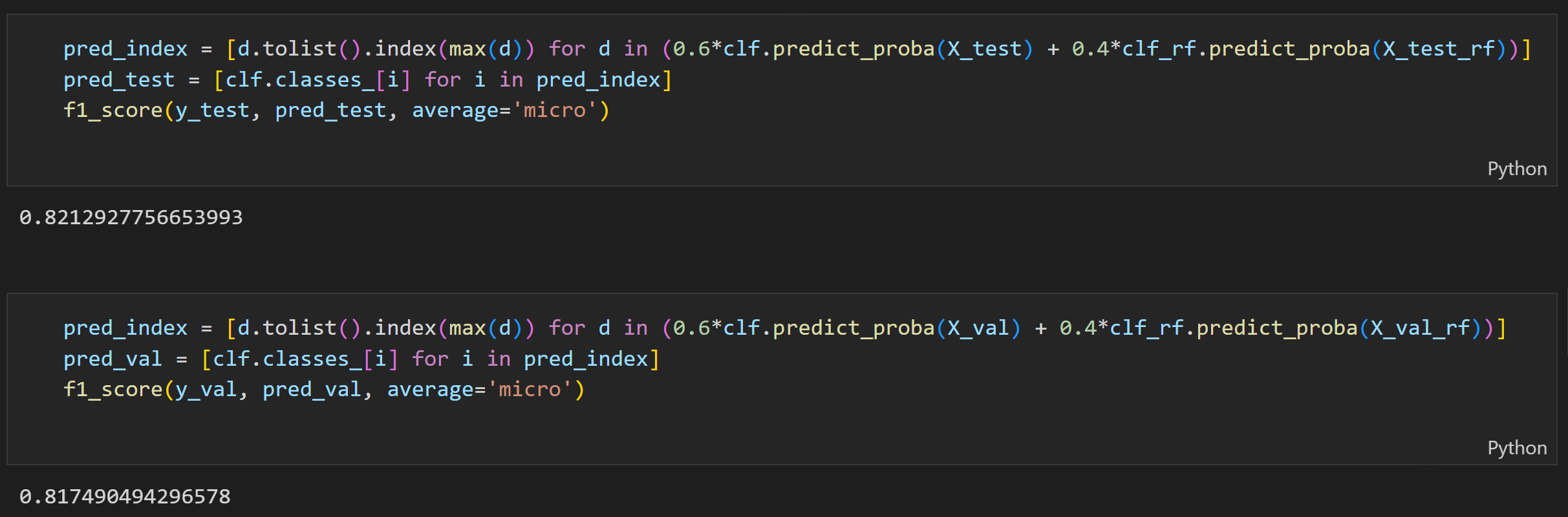
Model 3 (ensemble final model)#
In final model, I ensembled Model 1 and Model 2. When combining two models, I gave two weights for both models’ predicted probability.
From the following image, We can see that the overall accuracy on both testing and validation sets increases.
For more details about the code of the project, please refer to my GitHub Repository